What are transformers?
Transformers are machine learning models based on Deep neural networks that are powering the new age NLP applications like ChatGPT.
The 2017 paper from Google brain team (Vaswani et al) that introduced transformers to the world is linked here. The paper is aptly titled “Attention is all you need”.
The transformer models are successors to the previously popular Recurrent Neural Networks (RNNs), which were widely used for NLP applications before the transformers.
Recurrent Neural networks also made use of attention mechanisms but unlike RNNs, transformers do not have a recurrent structure. This means that with enough training data, attention mechanism alone can match the performance of “RNNs with attention”. Hence the title “Attention is all you need”
The main idea behind transformers is the idea of self-attention, which allows the model to understand the context of the words in a much better way.
As of now, Transformers are used in the field of both NLP and Computer Vision. In this article we will primarily focus on the NLP applications
Problems with RNNs
RNN needed to process tokens sequentially maintaining a state vector that contains a representation of the data seen prior to the current token.
In practice due to the vanishing gradient problem the model’s state at the end of a long sentence makes it impossible to extract any precise information from the preceding tokens.
Dependency on previous token computations also makes it hard to parallelize the computation on modern deep-learning hardware. This makes training them inefficient.
Hello Self-Attention
Understanding Attention
Attention is nothing but the weights a neural network assigns to each element of a sequence. The process to calculate these weights is called attention mechanism.
Self part refers to the fact that these weights are calculated for all hidden states in the same set, for example all hidden states of the encoder. Whereas the attention in RNNs is calculated by computing the relevance of each encoder hidden state to the decoder hidden state at a given decoding timestamp. In Transformer architecture encoder attention is not dependent on the decoder.
The main idea behind self-attention is that instead of using a fixed embedding for each token, we can use the whole sequence to compute a weighted average of each embedding.
Attention function
Attention function is described as mapping a query and a set of key-value pairs to an output, where query, keys, values and output are all vectors.
The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key
Analogy
Here’s an analogy to help explain query, key, and value vectors in the context of the attention mechanism used in the transformer architecture.
Imagine that you are a student preparing for an exam, and you need to ask your teacher for help. Your teacher has a lot of knowledge about the subject, so you need to ask the right questions to get the most relevant information.
In this analogy, your questions are like the query vectors in the attention mechanism. They represent what you are looking for or what you need help with. The teacher’s knowledge is like the key vectors. They represent the information that the teacher has and are used to compute the similarity between the query and key vectors.
The teacher’s responses to your questions are like the value vectors. They represent the information that you actually receive from the teacher and are used to compute the weighted sum of values based on the attention weights.
In summary, the query vectors represent what you are looking for, the key vectors represent the information available, and the value vectors represent the actual information received. The attention mechanism calculates the similarity between the query and key vectors to determine which pieces of information are most relevant to the query, and then uses the attention weights to compute the weighted sum of the relevant values.
Transformer Architecture
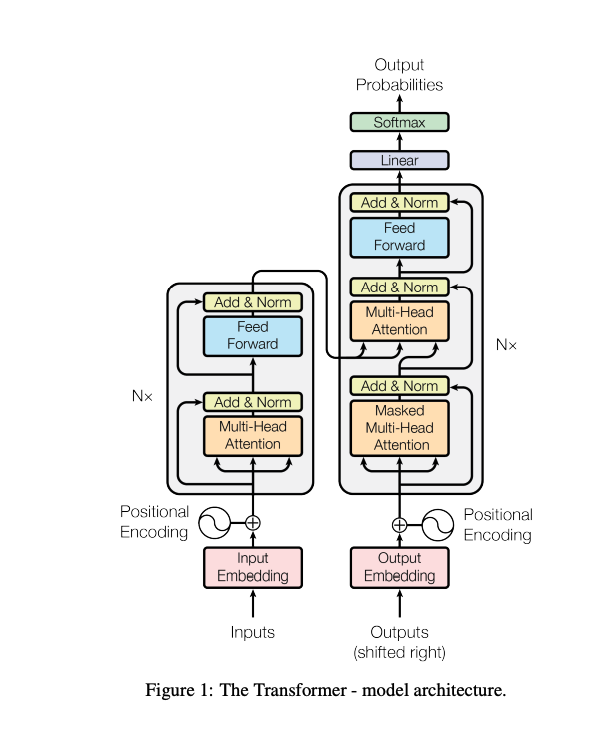
Transformers consists of prominently two layers, encoder layer and the decoder layer.
Encoder
Encoder converts the input sequence of tokens into a sequence of embedding vectors, also called the hidden state or context. The Encoder is composed of a stack of N=6 identical layers. Each layer has two sub layers. The first is a multi head self-attention mechanism, and the second is a simple fully connected feed forward network. There are also residual connection around each of the two sub-layers, followed by layer normalization.
Decoder
Decoder uses the encoder’s hidden state to iteratively generate an output sequence of tokens, one token at a time. The Decoder is also composed of a stack of N=6 identical layers. In addition to the two sub-layers each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack. Similar to encoder layer there are residual connections around each of the sub-layers, followed by layer normalization.
The self-attention layer in decoder is modified to prevent positions from attending to subsequent positions. This masking, combined with the fact that output embeddings are offset by one position, ensures that the predictions for position i can depend only on the know outputs at positions less than i.
How it works
- The input text is tokenized and converted to token embeddings (vectors). In order to inject information about the relative position of the tokens, token embeddings are combined with positional embeddings that contain positional information for each token.
- The encoder’s output is fed to each decoder layer and the decoder then generates a prediction for the most probable next token in the sequence.
- The output of this step is then fed back to the decoder to generate the next token and so on until a special end of sequence (EOS) token is reached.
Originally transformers were designed for sequence-sequence tasks like machine translation, but both the encoder and decoder blocks were soon adapted as standalone models. Most of the transformer models are based on one of the following three types:
- Encoder-only
- Converts input sequence of text into rich numerical representation
- well suited for tasks like text classification or NER
- Examples – BERT, RoBERTa and DistilBERT
- Representation computed for a given token in this architecture depends on both left (before the token) and right(after the token) contexts.
- This is called bidirectional attention
- Decoder-only
- Family of GPT models belong to this category
- They can auto-complete a sequence such as “I love to play …”
- Representation for a given token depends only on the left context in this model
- They are also called causal or autoregressive attention models
- Encoder-Decoder
- Suitable for machine translation and summarization tasks.
- BART and T5 models belong to this class
- used for modeling complex mappings from one sequence of text to another.
How are they used in Natural Language processing?
Transformers are mainly used in
- Machine Translation
- Text Summarization
- Named Entity Recognition (NER)
- Question Answering (chatbot)
- Text Generation
- Biological Sequence Analysis
- Text Classification
- Video Understanding tasks.
What is the best way to get started with transformers?
Best way to get started with transformers is to use the transformers library published by HuggingFace. It also provides other transformer-based architectures and pre-trained models.
What does pre-trained mean?
In the context of chat GPT (Generative Pre-trained Transformer) models, pre-trained means that the model has been trained on a large amount of data before it is fine-tuned for a specific task like question answering
Introducing Hugging Face transformer Libraries
Hugging face provides a whole ecosystem of many transformers based models, libraries and tools. It is the best way to easily incorporate transformer models into your application.
It mainly consists of two parts: family of libraries and a hub. The libraries provide the code while the hub provides the pre-trained model weights, datasets and scripts for evaluation.
For python we will mainly use the transformers library to import transformer models into our project.
Now I will show how to use hugging face transformers library in python to perform text classification, Named entity recognition, Question answering, summarization and translation tasks.
Text classification
By default the text-classification pipeline uses a model designed for sentiment analysis but it also supports multi-class and multi-label classification
text = """I do not like this Sony camera which I bought from Thailand. It has a big spot on its screen and is very slow to start recording.
I want to return it get and get my money back. Can you get me in touch with a support person"""
from transformers import pipeline
classifier = pipeline("text-classification")
import pandas as pd
outputs = classifier(text)
pd.DataFrame(outputs)
label score
0 NEGATIVE 0.998821
Named Entity Recognition
Named entity recognition or NER identifies the words in the text that are either products, people, places or organizations etc.
ner_tagger = pipeline("ner", aggregation_strategy = "simple")
outputs = ner_tagger(text)
pd.DataFrame(outputs)
entity_group score word start end
0 ORG 0.978721 Sony 19 23
1 LOC 0.999865 Thailand 51 59
As you can see it easily identified Sony as ORG (organization) and Thailand as LOC (location)
Question Answering
ChatGPT is a prime example of a question answering system using transformers. Code below gives you a flavor of how you can incorporate similar capabilities in your applications.
reader = pipeline("question-answering")
question = "What does the customer want?"
outputs = reader(question=question,context=text)
pd.DataFrame([outputs])
score start end answer
0 0.336623 138 176 to return it get and get my money back
Summarization
Another good use case of transformers model is to summarize long texts. Below is a paragraph on real transformers from wikipedia which I have summarized using the transformers model.
text = """A transformer is a passive component that transfers electrical energy from one electrical
circuit to another circuit, or multiple circuits. A varying current in any coil of the
transformer produces a varying magnetic flux in the transformer's core, which induces a
varying electromotive force (EMF) across any other coils wound around the same core.
Electrical energy can be transferred between separate coils without a metallic (conductive)
connection between the two circuits. Faraday's law of induction, discovered in 1831, describes
the induced voltage effect in any coil due to a changing magnetic flux encircled by the coil.
Transformers are used to change AC voltage levels, such transformers being termed step-up or
step-down type to increase or decrease voltage level, respectively. Transformers can also be used
to provide galvanic isolation between circuits as well as to couple stages of signal-processing circuits.
Since the invention of the first constant-potential transformer in 1885, transformers have become essential
for the transmission, distribution, and utilization of alternating current electric power.[1] A wide range of
transformer designs is encountered in electronic and electric power applications. Transformers range in size
from RF transformers less than a cubic centimeter in volume, to units weighing hundreds of tons used to interconnect
the power grid
summarizer = pipeline("summarization")
outputs = summarizer(text,max_length=60,clean_up_tokenization_spaces=True)
print(outputs[0]['summary_text'])
A transformer is a passive component that transfers electrical energy from one electrical circuit to another circuit, or multiple circuits. Faraday's law of induction, discovered in 1831, describes the induced voltage effect in any coil due to a changing magnetic flux. Transformers are used to change AC voltage levels
Translation
Language translation is another area where the transformers excel in. Here is a quick way to use Hugging face transformers for language translation from english to german.
translator = pipeline("translation_en_to_de",
model="Helsinki-NLP/opus-mt-en-de")
outputs = translator(text, clean_up_tokenization_spaces=True, min_length=100)
print(outputs[0]['translation_text'])
Result -
Ein Transformator ist eine passive Komponente, die elektrische Energie von einem elektrischen
Stromkreis auf einen anderen Stromkreis oder mehrere Stromkreise überträgt. Ein unterschiedlicher
Strom in jeder Spule des Transformators erzeugt einen unterschiedlichen magnetischen Fluss im
Transformatorenkern, der eine unterschiedliche elektrische Kraft (EMF) über alle anderen Spulen
verursacht, die um den gleichen Kern gewickelt werden. Elektrische Energie kann zwischen getrennten
Spulen ohne eine metallische (leitende) Verbindung zwischen den beiden Schaltungen übertragen werden.
Faradays Gesetz der Induktion, entdeckt 1831, beschreibt den induzierten Spannungseffekt in jeder
Spule aufgrund eines sich ändernden magnetischen Flusses, der durch die Spule umkreist wird.
Transformatoren werden verwendet, um Wechselspannungspegel zu ändern, solche Transformatoren,
die als Step-up oder Step-down-Typ bezeichnet werden, um das Spannungsniveau zu erhöhen bzw.
zu verringern... zu verringern. Transformatoren können auch verwendet werden, um galvanische
Isolation zwischen Schaltungen sowie zu Paarstufen von Signalverarbeitungskreisen zu bieten.
Seit der Erfindung des ersten konstanten potentiellen Transformators im Jahr 1885 wurden
Transformatoren für die Übertragung, Verteilung und Nutzung von Wechselstromstrom verwendet.[1]
Eine breite Palette von Transformatoren wird in elektronischen Netzen und in hunderten verwendet.
Where to go from here?
Transformers in themselves are a big area of research and this article just scratches the surface of what they are and what they can do. In order to understand them in detail I will recommend you to go through the original 2017 paper by Vaswani et al (“Attention is all you need”)
Other than this you can go through the Hugging Face website and try to understand other offerings and applications of their libraries
Lastly, if you just need to use the capabilities of transformers in your app, I will suggest you try to incorporate the hugging face transformers library in your own project. One suggestion is to use tweets and perform sentiment analysis and NER on them
Conclusion
I wrote this article during my research on this topic and what I found useful for myself to understand transformers. Hope this was useful for you as well. If you have any questions you can leave a comment below