What is Databricks
Databricks is an American Software company founded by the creators of Apache Spark. It provides a web based platform of the same name for working with Apache Spark, automated cluster management and iPython style notebooks.
Short History
It grew out of University of California Berkley in their AMPLab project which was involved in making Apache Spark(open source distributed computing framework built on top of Scala)
What is it used for ?
Databricks can be used for any of the below areas of Data Science:
- Data Engineering
- Data Science and Analytics
- Data Visualization
- Machine Learning and AI
I have built continuous streaming data pipelines using Databricks Delta live tables to stream the real time margin calculations on all portfolios operated by my firm. I will describe Delta live tables in detail in my subsequent post, hence bookmark this blog.
Databricks Offerings
First and foremost Databricks is a name synonymous with Apache Spark, as it provides a managed service where you can easily use Apache Spark on any of the major cloud platforms of your choice.
You can spin up spark clusters with any configuration you need. Then you can use iPython style notebooks to write your code in either Python, Pyspark, Scala or SQL.
Databricks provides a hassle free installation and usage of Spark, where you can focus on building your big data application instead of tinkering with infrastructure and dependency configuration.
Another unique feature offered by Databricks is the Delta Live tables which provides a way to continuously ingest raw data, preprocess and aggregate it in gold master tables. I will cover this in a separate post in detail
Koalas is an open source framework from Databricks that implements a pandas API on top of spark dataframes, allowing data scientists to easily transition their code from a single machine to a multi node cluster.
Databricks also offers another open source framework called Redash which can be used to query and visualize your data into beautiful dashboards.
Below I have listed all the services Databricks offers on all major cloud platforms like AWS, Azure and GCP.
- Data lakehouse platform
- A new paradigm that combines the concepts of Data lake and Data warehouse
- It is based on open source Apache Spark that allows analytical queries against semi structured data without a traditional database schema.
- Delta Engine
- A new query engine that layers on top of delta lake to boost query performance.
- Databricks SQL
- Serverless datawarehouse on the databricks lakehouse platform, lets you run all SQL and BI applications at scale
- Streaming Analytics
- Perform analytics on real-time streams of data
- Apache Spark
- The underlying language that powers the lightning fast processing of your data
- Koalas
- Pandas API on top of spark dataframes
- Redash
- Used to query and visualize your data into beautiful dashboards
- MLFlow
- It is an open source platform to manage complete machine learning lifecycle
- Delta Lake
- Single home for structured, semi-structured and unstructured data
- Based on open format storage layer for both streaming and batch operations
- Combines reliability (ACID transactions), security (Active directory integration) and performance
- All data in Delta lake is stored in open Apache Parquet format
- Delta Live Tables
- Declarative pipeline development for building and managing data pipelines or fresh, high-quality data on Delta Lake.
- Delta Sharing
- It is the industry’s first open protocol for secure data sharing with other organizations regardless of where the data live.
- It offers native integration with Unity Catalog
- Native Connectors
- Offers native connectors to mount mount cloud storage directly in your notebooks
- Easily ingest data into delta lake from all your applications, databases and file storage
In summary, Databricks provides an end to end solution to cater to all your data processing needs in the cloud.
How to get started with Databricks on Azure
Databricks offers 14 day free trial of their premium tier on any of the three major cloud platforms (Azure, AWS and GCP). I primarily use Databricks on Azure, hence I will describe below the steps to get started with your 14 day free trial of Databricks on Azure.
Step1: Go to databricks free trial link, fill in your details and follow the prompt to create a new Azure account (assuming you don’t have an azure account already). You will get a free $200 credit to spend on Azure services.
Please note you will be required to provide your credit card details so be extra vigilant on your cost analysis page. You can set a budget if you want so that you do not get any financial surprises. I will cover the cost analysis aspect in a separate article.
A new Azure account provides $200 credit and a 12 month free usage of all their services to a limited extent.


Step2: Once you have your Azure account created with credit card details, you will see your first Azure subscription. Then you need to search for Databricks in the search bar and create a new Databricks workspace. Details are in screenshot below. You will also need to create a new resource group which you can create in the same form as shown below
Remember to choose the pricing tier as Trial which is available for 14 days.

After you submit the above form you will see the deployment in progress as shown below

Step3: Now you are ready to launch the Databricks workspace from the screen shown below.

Step4: Create compute cluster by following the prompts shown on the left hand side on the screen below

Press the create compute button as shown in the picture below.

Fill in the details as shown below. For some reason my cluster was not getting created so I had to add additional json settings to restrict the DBUs to be less than 1DBU/hr. You will see the DBU forecast in the Summary section on the right side. Below the screenshot I have added the additional json settings I used.
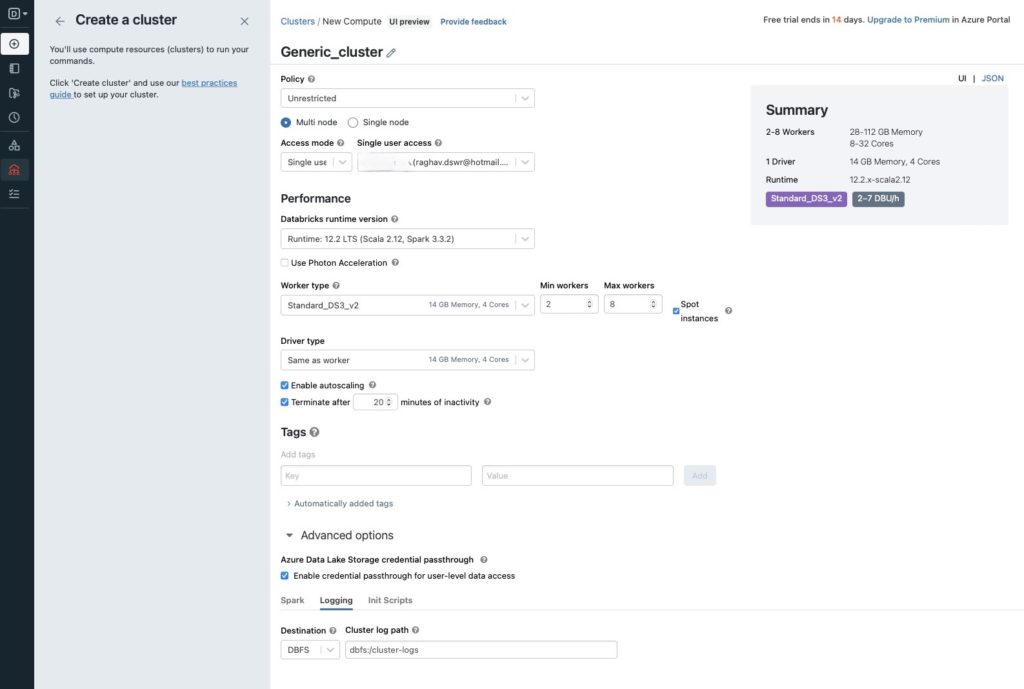
"clusters": [
{
"label": "default",
"node_type_id": "Standard_DS3_v2",
"driver_node_type_id": "Standard_DS3_v2",
}
],
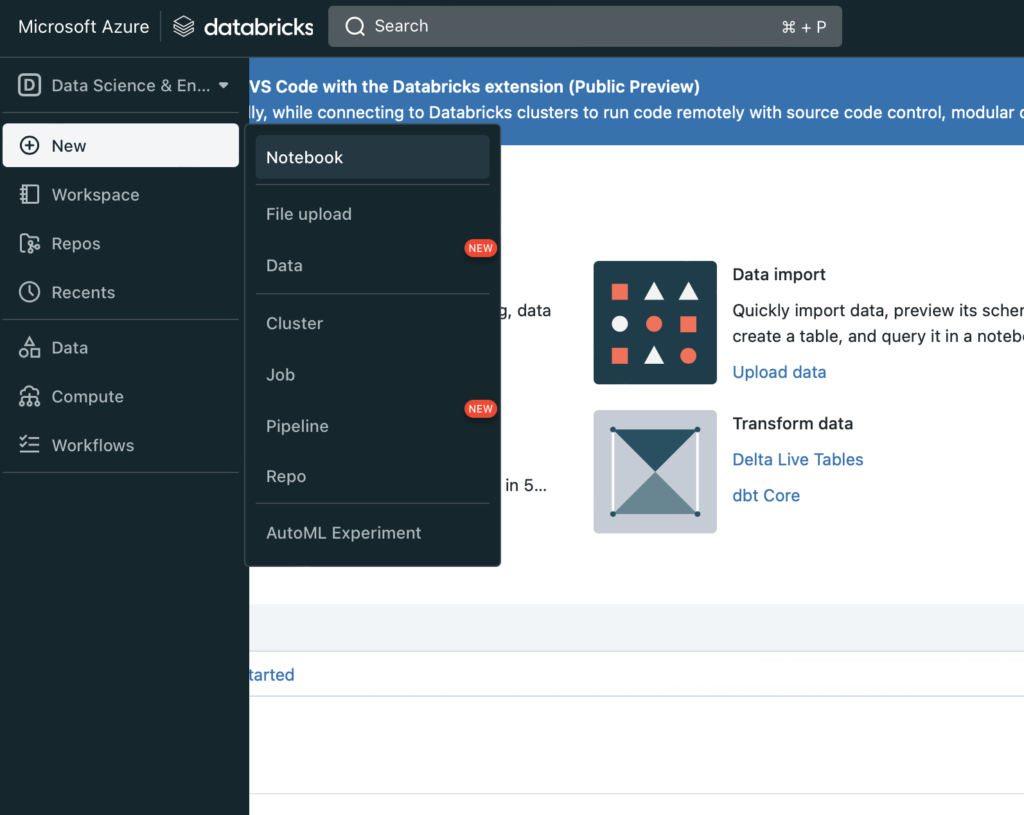
Step5: Now that cluster is created, you are ready to create your first notebook where you will write your code. Create your first notebook as shown below
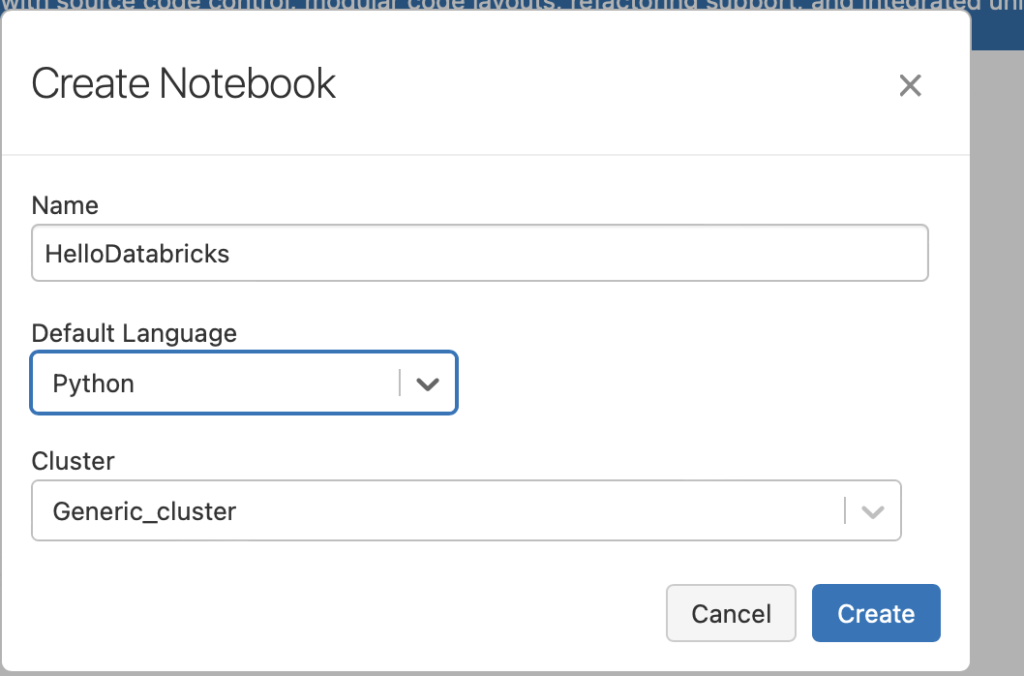
You will need to choose the default language and the cluster you just created.
Step6: You can add the below sample code and run your notebook from the Run All button. Code is pasted below the screenshot
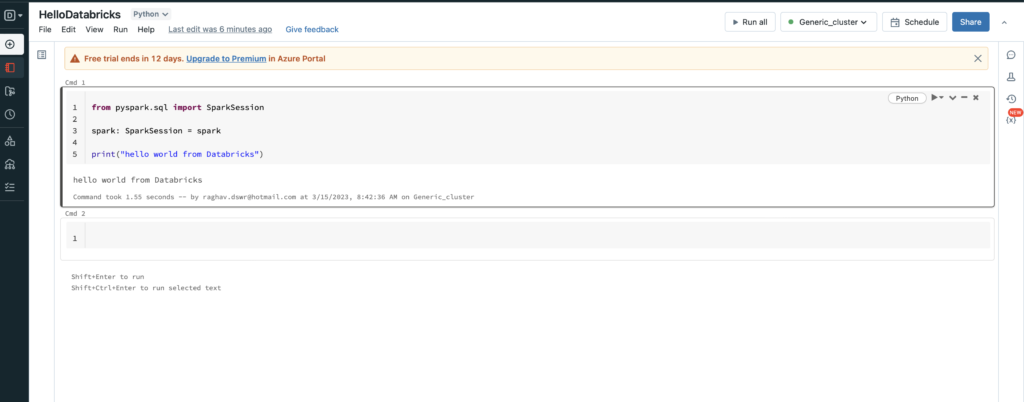
from pyspark.sql import SparkSession
spark: SparkSession = spark
print("hello world from Databricks")from pyspark.sql import SparkSession
spark: SparkSession = spark
print("hello world from Databricks")
Conclusion
This is all you need to do get started with Databricks on Azure for free. Hope you are able to get some value from this article. Please let me know in the comments below if you need any more details.
Happy coding!