This article covers two of the most important concepts related to execution of code in Apache Spark. It is crucial for your understanding of Spark and will enable you to write highly efficient code to make use of power that Spark provides
Transformation vs Actions and Lazy evaluation
Operations in Spark can be classified into two categories – Transformations and Actions
Transformations
Transformations are operations that transforms a Spark DataFrame into a new DataFrame without altering the original data. Operations like select() and filter() are examples of transformations in Spark. These operations will return a transformed results as a new DataFrame instead of changing the original DataFrame
Lazy Evaluation
All transformations are lazily evaluated by Spark, that means Spark does not execute any code until an Action operation is called. It simply records all the transformations as lineage. This ability to create a lineage, allows spark to evaluate the best strategy to optimize the code, rearrange and coalesce certain operations into stages for much more efficient execution.
Actions
Actions are operations that trigger the lazy evaluation of all recorded transformations (lineage). show() and count() are the examples of such Action operations which trigger the lazy evaluation
Table below shows examples of Transformations and Actions operations in Spark
| Transformations | Actions |
|---|---|
| select() | count() |
| filter() | collect() |
| map() | take(n) |
| orderBy() | top() |
| groupBy() | countByValue() |
| join() | reduce() |
| flatMap() | fold() |
| union() | aggregate() |
| intersection() | foreach() |
Fault Tolerance and Immutable DataFrames
Below diagram shows an example of three transformations and one Action in a chain. As each transformation produces a new immutable DataFrame, it allows Spark to continue execution from any point of failure.
Spark can easily reproduce the original state of a DataFrame by simply replaying the recorded transformations in its lineage, that makes it highly resilient when it runs on multiple worker nodes on a cluster.
The actions and transformation lineage contribute to the Spark query plan, which I will cover in upcoming posts. Nothing in the query plan is executed until an Action is invoked. Try out below code in Spark shell to experience the lazy execution of Spark in Python. Only when count is invoked the execution will start, until then it is just recording and waiting for the action!
#you will need a text file which contains the word Spark at least once to
#to get a non zero result
>>> strings = spark.read.text("AnyTextFileWithWords.txt")
>>> filtered_text = strings.filter(strings.value.contains("Spark"))
>>> filtered_text.count()
8
Narrow vs Wide Transformations
Transformations can be further classified into having narrow dependencies or wide dependencies. Any transformation for which a single output partition can be calculated from only one input partition is a narrow transformation.
For example filter() and contains() operations can produce output partition from a single input partition without needing any data exchange across the executors. Therefore, they are called narrow transformations.
However, transformations like groupBy() and orderBy() need data from multiple partitions and force data shuffle from each of the executors across the cluster before producing the output partition.
Below is a diagram showing narrow vs wide transformations. If you want to read more about Data partitions, you can checkout my earlier post here.
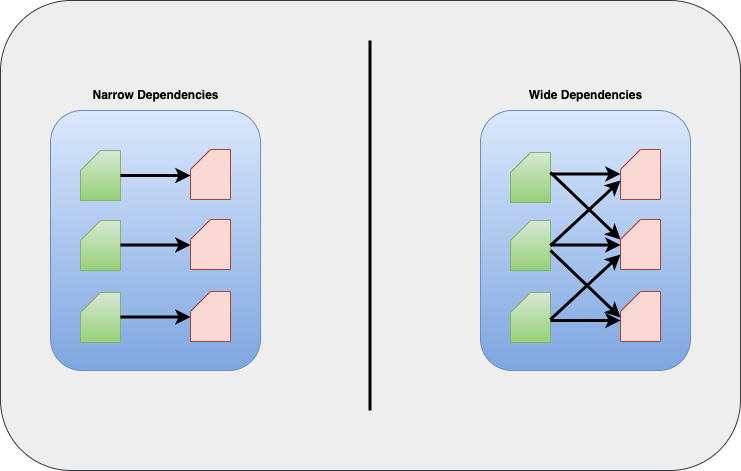
Narrow transformations are faster to execute as they can be readily parallelized across the executors whereas wide transformation wait for all executors to finish their map operation before beginning the shuffle and reduce operations. Knowing the difference will help you make better design decision while coding your Spark application. If you know the basics of Map Reduce you will get a better understanding of these concepts.
Conclusion
In this post I covered some of the basic concepts of Spark execution framework. Hopefully this post will help you design better Spark applications. Understanding these concepts is crucial for your career as a Spark developer. Please let me know your feedback in comments below.
Very well written, Raghav. Thank you for the post!