You might be wondering why did Google named its Deep Learning library as TensorFlow?
What are Tensors?
Are they just matrices?
What is the difference and what benefits they provide over matrices?
If you are pondering over any of the above questions in your journey of learning Deep Learning, you have come to the right place.
Introduction
In this post, we will explore some important differences between Tensors and Matrices and what properties of Tensors make them suitable for Deep Learning.
What are Matrices?
I think all of you are aware of Matrices from your linear algebra class. They are rectangular collection of elements, mainly numbers. They are the main driving force behind traditional data science and statistical analysis.
What is a Tensor?
Tensor is a matrix that lives in a structure connected to other elements of the same structure. That means if one element of the structure changes then other elements change as well
Not every matrix is a tensor but all Tensors can be represented as a generalized matrix.
The best explanation of Tensors is provided by Dan Fliesch in his Youtube video. I have the summary provided just below this video for your easy reference. But I would highly recommend to watch this video first and then come back to this post.
I have explained the use of Tensors in Deep learning with example below in later sections of this post.
Summary of Dan Fliesch’s explanation
- Tensors are a combination of Components and basis vectors, which makes them very powerful.
- All observers in all reference frames, agree, not on the basis vectors nor on the components, but on the combination of components and basis vectors.
- The reason is that basis vectors transform one way between reference frames, and the components transform in just such a way so as to keep the combination of components and basis vectors the same for all observers.
- It was this characteristics of the Tensors that caused Lilian Lieber to call tensors “The facts of the universe” in her book “The Einstein Theory of relativity” (Tensors are introduced in page 127 of this book – Thank you!)
Why Tensors are used in Deep Learning
I will tackle this question with below example.
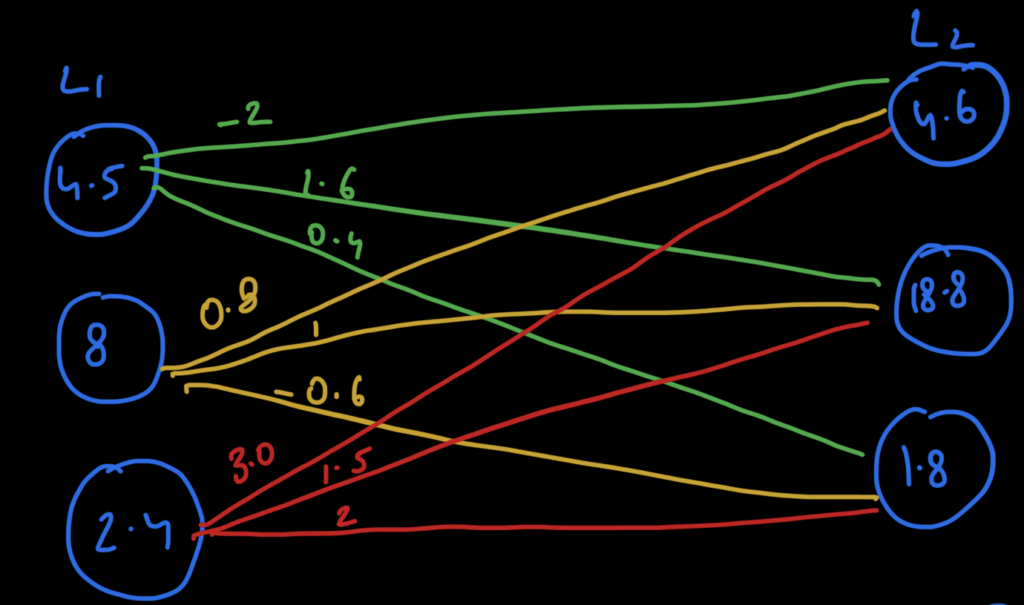
Below is a picture of a two layer network with three nodes in each layer, L1 and L2 respectively.
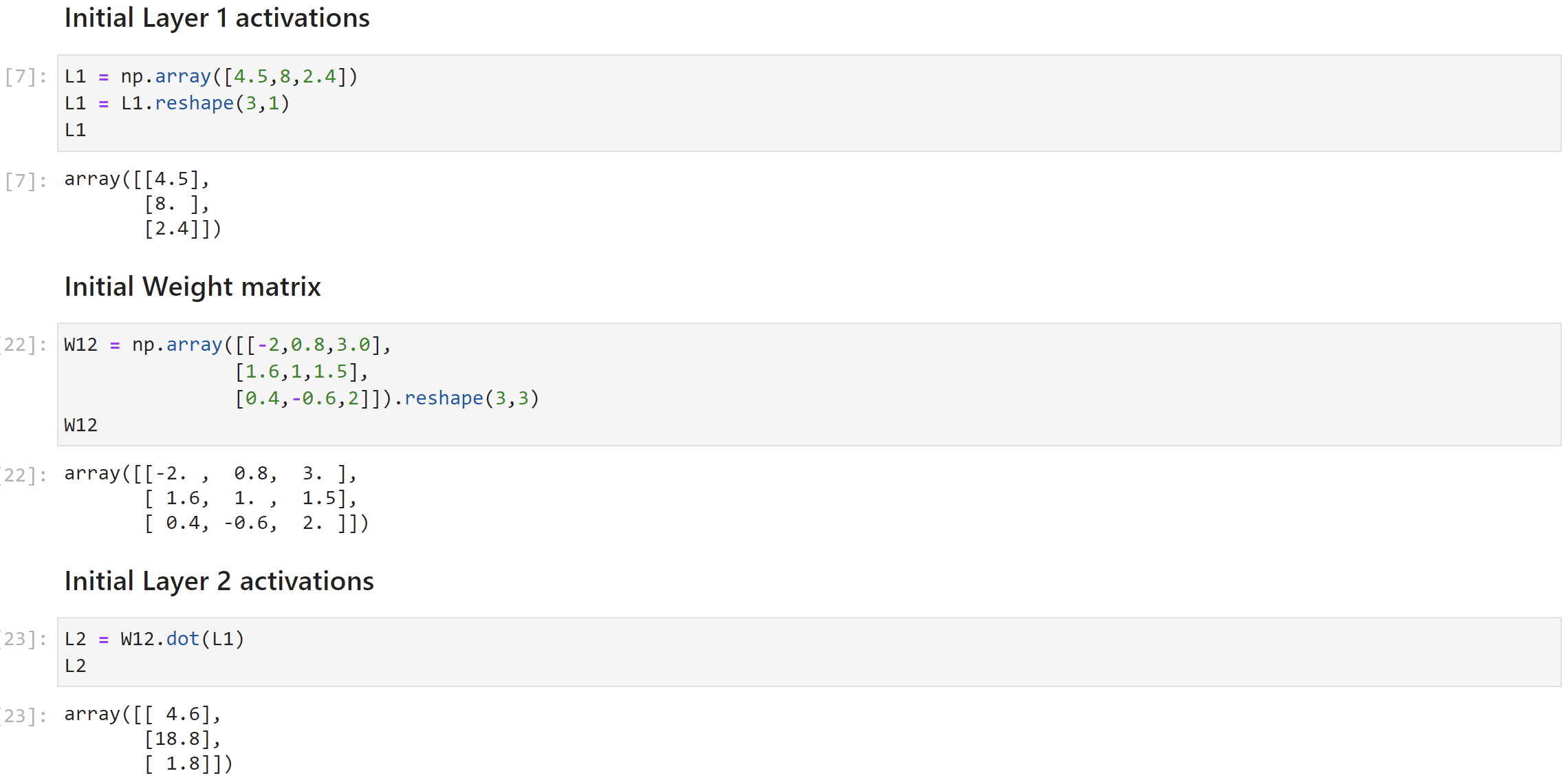
Inside the nodes are the activation values of that node and each connecting line has its weight depicted above the line. We can also represent these as Activation and Weight matrices as shown below the image with the help of a jupyter notebook. (You can download this notebook from my github repo here)
Github Repo link for below notebook – https://github.com/raaga500/YTshared/blob/master/V11_TensorsInDeepLearning.ipynb
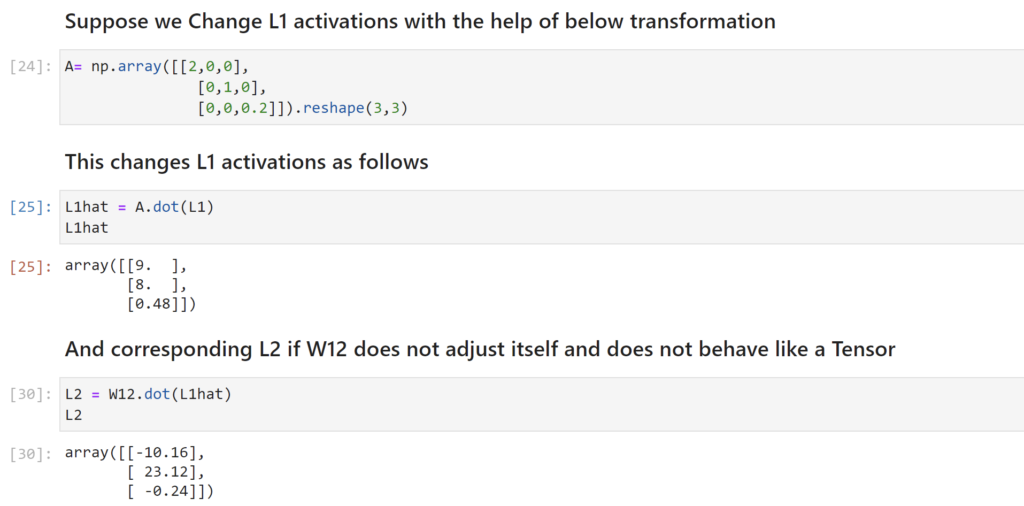
Conclusion
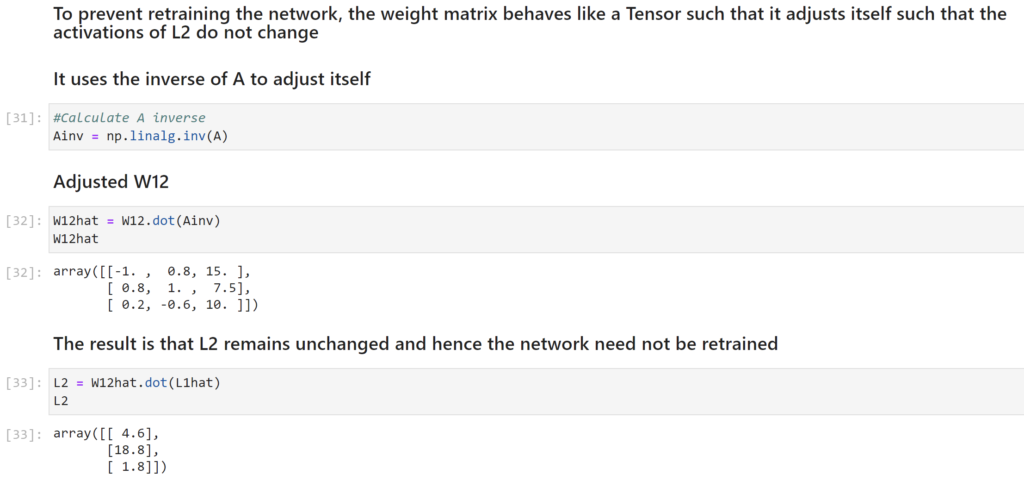
As shown above the property of the weight matrix to adjust itself in such a way that the network need not be retrained makes it very useful in deep learning. This behavior of the weight matrix makes it a Tensor and enables really efficient way to train Deep Learning networks.
Hence the name TensorFlow.
Hope you learned something new with this post. If you have any questions do comment below and soon I will also upload a Youtube video on my channel to explain it for those of you who prefer audio video explanations.
Until then stay tuned for my next post on this portal. Have a lovely day!