Scraping product prices data from Amazon is very helpful if you are building a price comparison utility or if you want to be alerted when the price drops below a certain threshold(just like honey). You can also store historical data of prices to analyse variation in prices on amazon. All this needs is you to automatically download product prices data from Amazon. In this blog post I will show you how to scrape prices from amazon for a certain product and store them in Pandas Data Frame using Python
Amazon does not like you to scrape data from their website hence they make it very hard using dynamic pages and may permanently block your IP address, if they detect you are a bot. Therefore proceed with caution! I would advise to have your script run overnight with random delays in between calls to their URLs. If you will be nice and do not act like a DDoS attack you may save yourself from their automated bot blockers. Another way is to use proxy servers with IP addresses which you don’t mind even if they get blocked.
Before we begin, I would highly recommend the book Web Scraping with Python if you want to really dig deep into web scraping in Python
Installing Beautiful Soup
First thing you need is the beautiful soup library. If you don’t already have it you can install it by running the below command in your python environment. This is the main library which will parse the html pages generated by Amazon and retrieve the prices tag.
pip install beautifulsoup4
Let’s import Beautiful Soup along with all other dependencies
from bs4 import BeautifulSoup import requests import random import time import pandas as pd
requests module is python’s standard library package to request URL and get response from the server. random and time module are used to generate random time delays in between calls to different Amazon URLs. pandas is the most popular data analysis library which will be used to store the retrieved prices in a tabular format.
Find the relevant price html tag
In order to retrieve the prices information for a specific product you need to know the html tag which Amazon uses to display the price. For this you need to go to the URL and manually inspect the html of the page and find out the tag. Let me show you with an example.
Let’s head over to the airpods pro amazon URL
https://www.amazon.com/Apple-MWP22AM-A-AirPods-Pro/dp/B07ZPC9QD4/
Once you are at this page inspect the page by pressing F12 if you are on chrome (might work on other browser also)
You will see the side window open on the page with the html code of that page. Press Ctrl+Shift+C to inspect individual items on the page or just press the button highlighted in red box in below screenshot. This will let you hover over the html page elements and will highlight the part of html code that is responsible to display that page element.
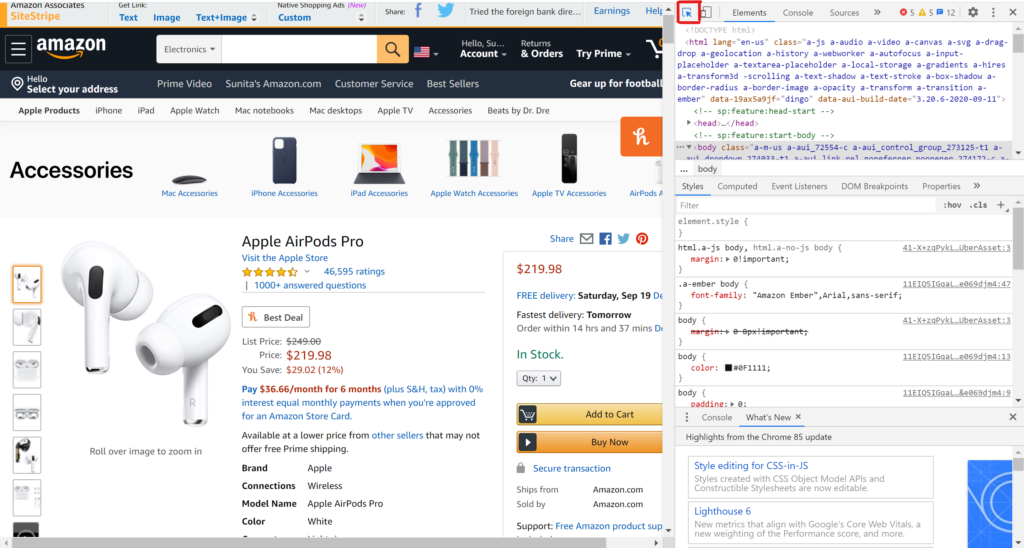
Once you have enabled element wise inspection just click on the price on left side page currently showing as $219.98 in the above screenshot. You will find that the corresponding html code is highlighted in the right side inspection window(as shown in the screenshot below)
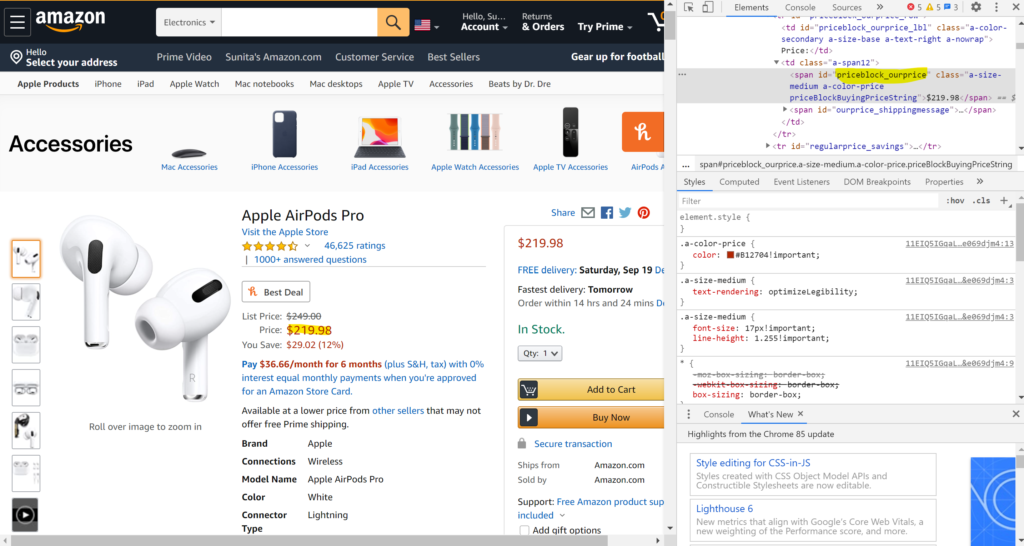
From the html code copy the span id “priceblock_ourprice” (highlighted in yellow). We will need this while parsing the html code using beautiful soup.
Retrieve the URL using python
Now we will use the request library of python to programmatically retrieve the html of the Amazon product URL. This is the step where you will hit the Amazon servers and you need to be careful not to send too many requests in a short span of time. For which we will use the random delay functionality.
Before we can proceed with request we need to create a header dictionary variable which will store our user-agent string. It contains information on the user who is trying to access Amazon, and you need to make sure that you are imitating an actual person and not a bot. For this you will also need the version of your browser which you will need to update in the user-agent string as shown below (mine is ‘Chrome/83.0.4103.97’).
headers = {
'authority': 'www.amazon.com',
'pragma': 'no-cache',
'cache-control': 'no-cache',
'dnt': '1',
'upgrade-insecure-requests': '1',
'user-agent': 'Chrome/83.0.4103.97',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'none',
'sec-fetch-mode': 'navigate',
'sec-fetch-dest': 'document',
'accept-language': 'en-GB,en-US;q=0.9,en;q=0.8',
}
Also let’s store the URL of the products we want to track. I am tracking three products here.
airpods_pro_url = 'https://www.amazon.com/Apple-MWP22AM-A-AirPods-Pro/dp/B07ZPC9QD4/' airpods_url = 'https://www.amazon.com/Apple-AirPods-Charging-Latest-Model/dp/B07PXGQC1Q' apple_watch_url= 'https://www.amazon.com/Apple-Watch-GPS-Cellular-44mm/dp/B07XK1XX1K' target_products = ['airpods_pro','airpods','apple_watch'] target_urls = [airpods_pro_url,airpods_url,apple_watch_url]
Now we can use the requests.get function to retrieve the html pages of these products
url = target_urls[0] response = requests.get(url,headers=headers)
If everything went well, you will get a response code of 200. You can check it using below command
print(response.status_code)
Using Beautiful Soup to retrieve prices
By now you have requested the URL from amazon and retrieved the response. Next step is to read this response using beautiful soup library to retrieve the price. In this blog post I will just show you the commands you can use to retrieve any element with an id from html page. Beautiful soup in itself is vast library and books are written just to showcase it’s full functionality. The book that I mentioned above contains good amount of detail on beatiful soup.
Below is the command to retrieve price and title information from the response we just got from Amazon using our request. As you can see I am using the html tag “priceblock_ourprice” which we retrieved earlier.
soup = BeautifulSoup(response.content,"lxml")
price = soup.select('#priceblock_ourprice')[0].get_text()
title = soup.select('#title')[0].get_text().strip('\n')
print('Price for {} is {}'.format(title, price))
And here is the output
Price for Apple AirPods Pro is $219.98
Time Delay
Next thing we need is a way to introduce delays in our multiple requests to amazon. For this we use random and time libraries of python. Below is the code
sleep_times = [60,120,30] sleep_time = random.choice(sleep_times) time.sleep(sleep_time)
This code randomly selects either 60, 120 or 30 seconds of delay in multiple requests to amazon. We will use it later when we put all of this in a for loop.
Crawled Date Time function
Along with this we will also need the time when we crawled the page so lets create a function which gives us the crawled time in nice format. We will use it to store the information in our data frame. Below is the function
import datetime
def get_current_datetime():
now = datetime.datetime.now()
d1 = now.strftime("%Y%m%d_%H%M%S")
return d1
This function will return datetime in below format
'20200623_144339'
Storing Scraped Data in a Pandas DataFrame
Lastly, we need functionality to store scraped information into a Pandas dataframe for further analysis
scraped_date_time = get_current_datetime() row = [scraped_date_time,url,target_products[index],title,price] df_length = len(price_history_df) price_history_df.loc[df_length] = row
The Complete Solution
Now we have everything to put together in a loop so that this script can download and store data. Below is the complete code
from bs4 import BeautifulSoup
import requests
import random
import time
import pandas as pd
import datetime
def get_current_datetime():
now = datetime.datetime.now()
d1 = now.strftime("%Y%m%d_%H%M%S")
return d1
headers = {
'authority': 'www.amazon.com',
'pragma': 'no-cache',
'cache-control': 'no-cache',
'dnt': '1',
'upgrade-insecure-requests': '1',
'user-agent': 'Chrome/83.0.4103.97',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'none',
'sec-fetch-mode': 'navigate',
'sec-fetch-dest': 'document',
'accept-language': 'en-GB,en-US;q=0.9,en;q=0.8',
}
sleep_times = [60,120,30]
price_history_df = pd.DataFrame(columns=['crawled_datetime','url','product_name','title','price'])
for index,url in enumerate(target_urls):
print('Checking price for',target_products[index])
scraped_date_time = get_current_datetime()
response = requests.get(url,headers=headers)
sleep_time = random.choice(sleep_times)
if response.status_code ==200:
soup = BeautifulSoup(response.content,"lxml")
price = soup.select('#priceblock_ourprice')[0].get_text()
title = soup.select('#title')[0].get_text().strip('\n')
print('Price for {} is {}'.format(title, price))
row = [scraped_date_time,url,target_products[index],title,price]
df_length = len(price_history_df)
price_history_df.loc[df_length] = row
if index<len(target_urls)-1:
print('Waiting for {} minutes for next hit'.format(sleep_time/60))
time.sleep(sleep_time)
When you run this script continuously with a set frequency it will keep on adding data points to the pandas dataframe, just make sure the the pandas dataframe is declared as a global variable.
Below is a sample dataframe created from this script

This is it! In this post we learned how to scrape prices from Amazon for select products and store them in a dataframe. We can also use scrapy which is a much more sophisticated library to write scrapers and crawlers. I will write another blogpost on how to use scrapy. Do bookmark or subscribe to this blog for getting alerted when I post new blogs.
Hope you enjoyed this post. Do let me know your thoughts in the comments.
One Reply to “How to scrape product prices data from Amazon and store it in a pandas DataFrame using Python”