Pandas which is a well-know library for data analysis in Python also contains robust functionality to read data from various external sources. Usually when Data Scientists think of Data Scraping, Beautiful Soup library is the one that comes to their mind. However, they skip using one of the tools they already use extensively i.e. Pandas. Yes Pandas can also be used to scrape data from internet. But it works well only if the data present on a URL is in a tabular format.
When data is contained in tabular format on an internet URL, Pandas can intelligently retrieve that and store only the relevant parts in the data frames. This is very handy when you are doing financial or sports analysis, where data is usually contained in a tabular format.
Before we begin I would like to highlight my recommendation for the best book for learning Pandas and other data analysis tools in python. Python for Data Analysis by Wes Mckinney is one the best as it is written by the creator of Pandas itself.
For those who don’t have pandas installed you can install it using following pip command in their python environment.
pip install pandas
If you are working in a jupyter notebook, then you can run the above command with an exclamation mark at the beginning (which is a shortcut to run system commands from the jupyter notebook).
!pip install pandas
Scraping Financial Data from Yahoo.com
Let’s learn this with an example. Suppose you are looking at the stock information on Yahoo about stocks which gained on a given day. Given below is the link and a screenshot of how the data looks like on Yahoo
https://finance.yahoo.com/gainers
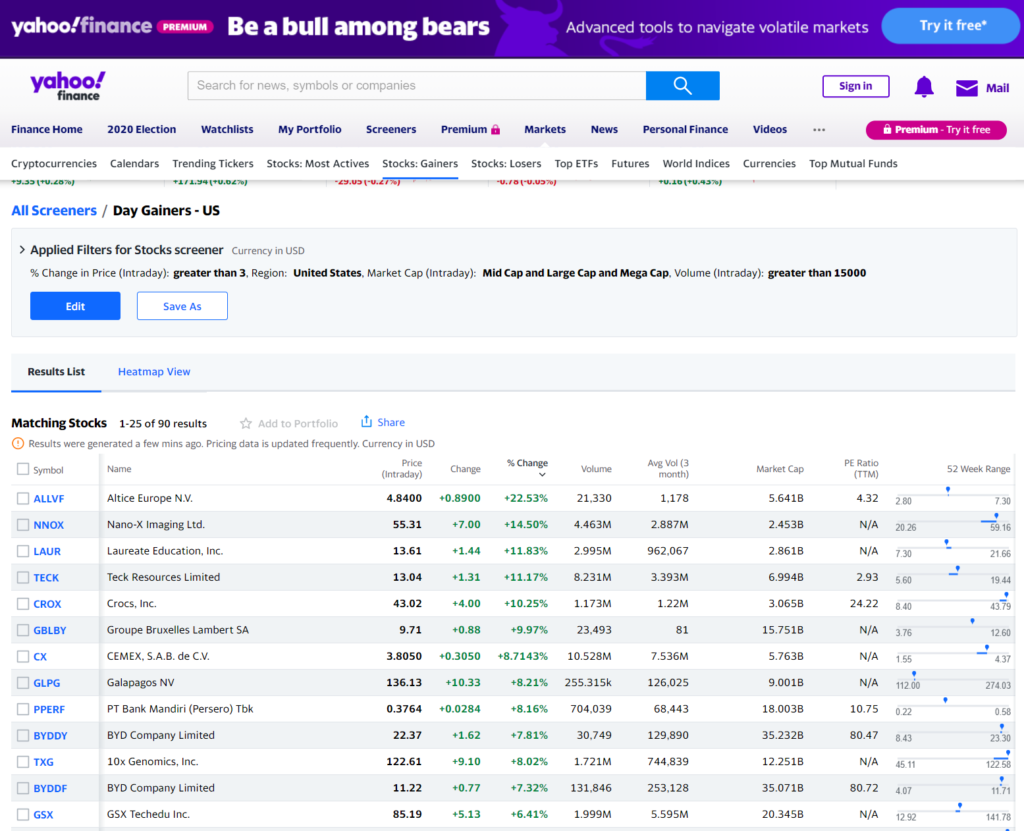
Now as a data scientist you are interested in the stock table you see on the bottom half of the screen. You can easily import this table in pandas with a simple command. The API you will need to use is read_html as shown below:
import pandas as pd
stock_gains = pd.read_html('https://finance.yahoo.com/gainers')
And below is how the data looks like when you check the contents of the variable stock_gains
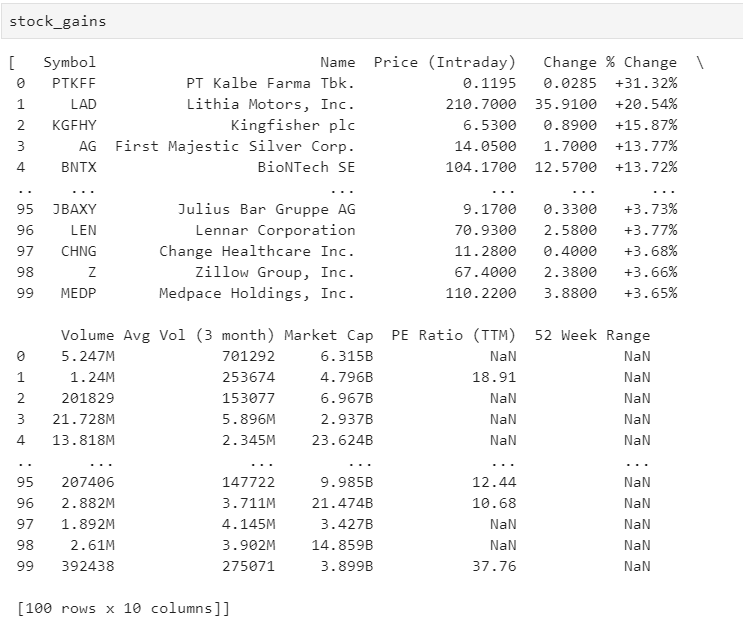
Some times the server call returns only a subset of rows, you can play with the URL to see the query parameters to extract more data. Following is the URL you can use to get 100 rows instead of default 25
stock_gains = pd.read_html('https://finance.yahoo.com/gainers?offset=0&count=100')
The function read_html retrieves all tables in the given URL and stores them inside a list type variable. If you check the type of stock_gains you will see that it is a list.
type(stock_gains)
In this example URL we have only one table so if you check the length of the stock_gains variable you will see that it has only one element.
len(stock_gains)

Just select the first element in the list to get the dataframe
stock_gains_df = stock_gains[0]
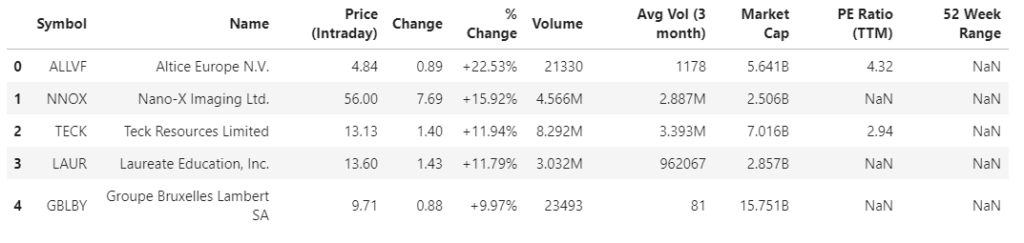
Here are the first 5 rows in your dataframe now
stock_gains_df.head()
This is it for this example. Let’s see another example where you have multiple tables in single URL
Scraping cricket stats from the ESPNCricInfo
This time I am going to scrape some statistics for Virat Kohli (the captain of Indian cricket team) from ESPN Cricinfo from below URL
https://www.espncricinfo.com/india/content/player/253802.html
As you see on this page there are multiple tables with stats for Virat kohli. Pandas read_html function is intelligent enough to recognize multiple tables and store them in a list.
virat_stats = pd.read_html('https://www.espncricinfo.com/india/content/player/253802.html')
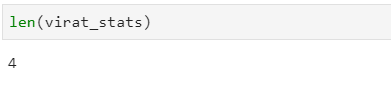
As you can see there are 4 tables recognized on this page and Pandas has stored them separately in a list
Now you can get them in to individual dataframes using the same command as above. Examples are shown below
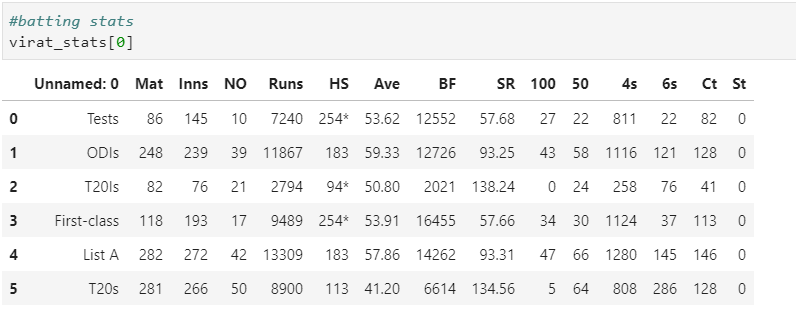
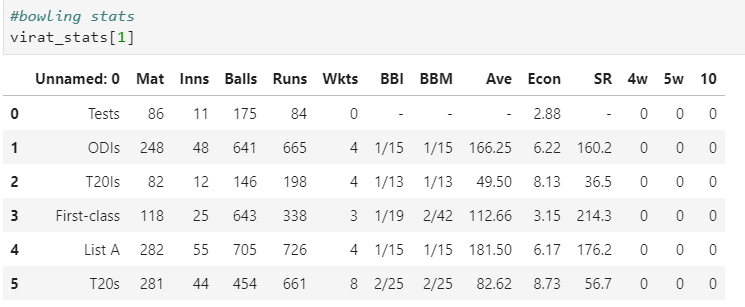
And if you want to learn more about the functionality offered by read_html function of pandas then you can check the documentation below
https://pandas.pydata.org/pandas-docs/version/0.23.4/generated/pandas.read_html.html
There you have it! You learned the simplest way of getting tabular data from URLs into pandas dataframes.
In the next post we will see how we can use BeautifulSoup library to scrape news data from news websites. Specifically Zeenews.com and also how to modify it to run for ndtv.com and other news websites.